Verifying Asset Accuracy
A reader writes:
“What is the industry standard way of calculating ITAM accuracy?”
I’m not sure about the ‘industry standard’ way, but I’ll share techniques I’ve used in the past, hopefully others can chip in their recommendations in the comments section too (Note: The focus of this article is to verify hardware).
Verified inventory is one of the seven key ingredients for SAM success:
- Authority
- Internal resource
- Good, verified inventory
- Good, verified license records
- A License reconciliation process
- License expertise
- Executive group to drive change
Without verifying inventory, IT teams may be sceptical of its accuracy. The International Standard for SAM ISO/IEC 19770-1 is broken into four chunks, the first of which is ‘Trustworthy Data’. Without trust, we can’t make confident decisions and license reconciliation results won’t be strong enough to defend against audits (Software publishers will use their own tools to determine accuracy if your data looks dodgy).
Without trustworthy data:
- IT Asset Managers are not taken seriously. They are supposed to be quartermasters of the IT assets of the organisation, yet they can’t demonstrate a good view of assets.
- Poor data undermines their role and they end up being by-passed on key projects and deployments
- The ITAM role is seen as bureaucratic – admin with no real purpose – because their data lacks no useful purpose.
Verifying Asset Accuracy
So how do we verify asset data to verify accuracy?
For me there are three primary methods:
- Physical spot-checks
- Lifecycle checks
- Comparing asset data with other sources
Physical checks
It’s always useful to physically ‘eyeball’ small samples of assets to verify the accuracy of your larger estate. So for example you could go out and verify your records for 20 devices at random and to measure the accuracy of your records.
Lifecycle Checks
Another trick to verify asset accuracy on an on-going basis and constantly cleanse asset data is to ask the Service Desk or other IT teams to verify asset data during their usual day-to-day ITSM processes. For example a service desk analyst could easily verify the ownership of the asset when raising a ticket against it, check department, check the specification or configuration, the data supporting an asset being placed in stock could be checked and so on.
Comparing Data Sets
To verify asset data on a large scale – compare it against other data sets. For example in the diagram below we are comparing inventory data with SCCM data and Active Directory accounts.
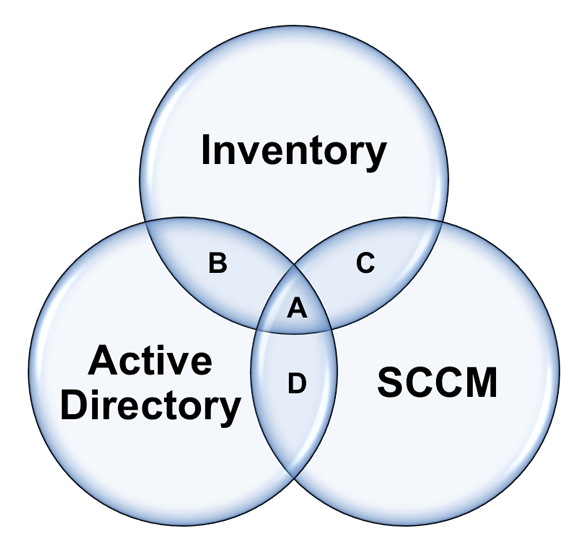
This generates some useful disparities:
- A – Hopefully this is the majority of your assets. They exist in your inventory tool, Active Directory and SCCM. If you have inventoried assets in this data set who have been seen recently (say within 90 days) and the data has occasional spot checks – I would call this VERIFIED data.
- B – The asset exists in Active Directory and your inventory tool, but does not exist within SCCM. There might be perfectly good reason for this – if not this is an exception your SCCM team will want to know about and adds credibility to both your data and your job role.
- C – An asset exists within your inventory tool and also has an SCCM agent – but does not exist within AD. Again, there might be perfectly legitimate reason for this, if not, this is valuable data for your security team to be aware of.
- D – Finally, perhaps devices exist within AD and also have an SCCM agent installed but do not have your inventory tool installed – this is exactly the exceptions you are looking for and addressing them will increase your accuracy.
You could also use anti-virus, data centre network scans, and comparing SCCM with MAP or any number of others sources to verify data.
If there is a legitimate reason for a device not being in one of these data sets, it should be recorded in your asset register so you don’t need to count it the next time.
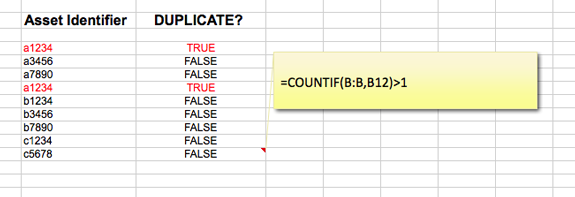
Some ITAM tools can help with this verification reporting, but many can’t. Whilst a little cumbersome for big networks Microsoft Excel can be used to run the reports. For example =COUNTIF can be used to identify duplicates in a list of assets (Good for cleaning up and verifying inventory) and =VLOOKUP can be used to compare two sets of data and identify an asset that DOES NOT exist in two sets of data.
Continual Service Improvement – Reporting by Exception
The real progress is made with this verification process when it is done on a regular basis. See the report card from a live environment over a 9-month period below. You can see from the table that the organisation is tracking four key metrics in order to verify the quality of asset data.
- How many devices have we got in inventory
- How many devices exist in AD but not in our inventory
- How many devices have we NOT audited (Agent failed, picked up by auto-discovery or network scan but not inventoried and so on)
- AWOL – devices whereby the inventory agent has not shown a communication or heartbeat back to the server in over 90 days.
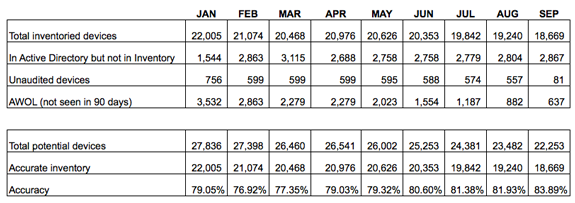
Depending on your environment, some may make progress quicker than this, for some it may take a longer. But the most important thing is that we can demonstrate IMPROVEMENT. This greatly increases the credibility of our data and therefore the credibility and usefulness of our ITAM practice.
What is your view? any other tips for verifying asset data?
About Martin Thompson
Martin is also the founder of ITAM Forum, a not-for-profit trade body for the ITAM industry created to raise the profile of the profession and bring an organisational certification to market. On a voluntary basis Martin is a contributor to ISO WG21 which develops the ITAM International Standard ISO/IEC 19770.
He is also the author of the book "Practical ITAM - The essential guide for IT Asset Managers", a book that describes how to get started and make a difference in the field of IT Asset Management. In addition, Martin developed the PITAM training course and certification.
Prior to founding the ITAM Review in 2008 Martin worked for Centennial Software (Ivanti), Silicon Graphics, CA Technologies and Computer 2000 (Tech Data).
When not working, Martin likes to Ski, Hike, Motorbike and spend time with his young family.
Connect with Martin on LinkedIn.
When it comes to data, accuracy is often a misunderstood term. This article describes more about completeness i.e. ‘do I have everything I need?’. Using this definition, the comparison of multiple sources is a good way to cast your net wider. But you have to ask the question which data source takes precedence in the event of discrepancies. In other words, what do I trust more?
You also need to factor in how often these data sources are updated, who by and how (e.g. manual data runs the risk of human error). Using the examples above, if SCCM data is collected on the 1st of the month and the inventory tool on the 19th then it stands to reason that there will be a discrepancy.
Accuracy relates to whether or not the data I have is actually right (e.g. I am reporting 2 CPUs and 4 cores and not the other way around).
Looking at the wider ‘quality management’ of data there are a number of areas to consider, in no particular order:
• Relevance – do I really need this data?
• Accuracy – is it right?
• Reliability – can I trust it?
• Validity – is the data in the correct format?
• Consistency – am I getting the same answer when I expect to (whether it’s right or wrong)?
• Availability – am I getting the data when I need it?
• Efficiency – is the effort to process the data worth the outcome or is there a better way? (Automation etc.)
There isn’t really any industry standard way to measure any of these things, some of it will be common sense and some will depend on your own data sources. But if you ask yourself these questions it will give you a feel for your overall confidence in the data and establish a baseline for you to work up from.
Hi Martin, thanks, great read.
I used a tool that covers what you have described in Point 3 (Comparing Data Sets) recently, it identified gaps in our processes and data which we were able to put a plan together to remediate. We used the tool as a one off to ascertain the quality of our data before embarking on an ITAM tool deployment. Our intent is to subscribe long term in order to keep the data quality issue in check and eventually to build a scorecard of data accuracy which will support many initiatives, including ITAM & ITSM. I work for a global enterprise – if anyone’s interested in the details please reach out to me.
I would like to add that – if you’re ITAM function is license compliance – then ‘asset accuracy’ should be directly related to the cost-risk that the asset represents. Let me explain….
For desktops, the typical cost-risk is Office + OS; that’s less than $400 USD at most.
For Servers, the cost risk is typically SQLServer, where then ENT ed is about $30K ( 4 cores on a physical device).
Right there, we’re looking at about 100:1 ratio where the cost of missing 1 SQLServer is like missing 100 desktops. Therefore, Asset Accuracy for Servers should be much, much higher than any desktop Asset Accuracy.
In fact, it’s the VMHost/Hypervisor that represents the ultimate 100% Asset Accuracy, and – in many cases – the VMHOST attributes (and thus VM Server relationships) are neither represented in SCCM nor the AD. Wow! Thus, that Venn diagram is non sequitor when it comes to determining the asset accuracy of the largest cost-risk devices: Vmware Host servers.
Another point is age-creep found in both SCCM and AD; all too often, Network administrators do not ‘flush’ out the the ‘zombie’ devices that are the remnant identifiers of device re-imaging and/or retirement.
The last suggestion is ‘shadow’ duplicates within the last 90 days ( using your example). Assuming you use a 90 day cut off; any device re imaged within those 90 days will be double-represented in the inventory. Such devices may look different – in both AD and SCCM- because the have a different device name and/or OS …. but in fact you’re seeing the same physical device -before and after an OS refit or complete re-imaging. the only way to knock out these shadow duplicates is to compare the BIOS serial numbers from your network management tool ( it can’t be affected by re-imaging or OS upgrades)
Hi Martin,
As a partial solution for this we have in Miradore ‘Asset data mismatch reporting’ feature that can be used for detecting and fixing accuracy errors. It is more explained in this blog post: http://www.miradore.com/blog/detect-fix-outdated-asset-data-data-mismatch-reporting/
Ryan is absolutely right in the points he makes but I would go one step further in so much that if your de facto source of truth the CMDB should be driven by your Asset Register. How much confidence in accuracy does an end client have around the data integrity of the CMDB.
With multiple data sources it needs to be qualified against your source of truth, not only for how many “hits” you get back in terms of OSI’s but to qualify that the install status is still relevant since the inventory data was collected (i.e. has the OSI been disposed/ retired).
This needs to be a fundamental step in the data import QA process.
Regarding IT Asset Management in an Enterprise (global) environment – What is the current (2019) Industry Standard of IT Inventory Accuracy?
[…] off of faulty numbers. It will undermine the authority of your whole SAM process; you can test the accuracy of your data through physically spot-checking, asking for lifecycle updates from the IT teams, and comparing […]